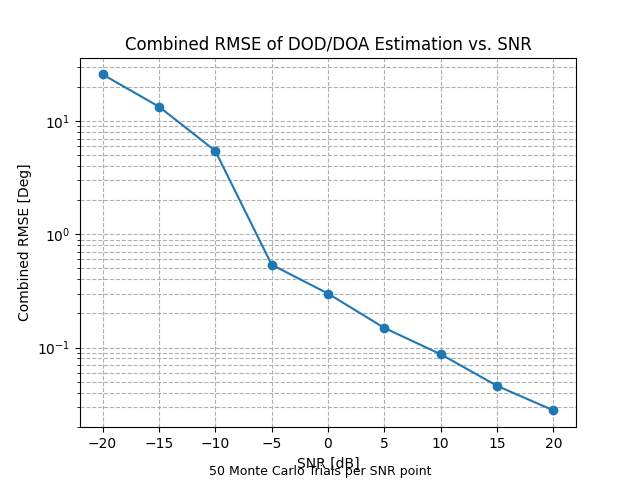
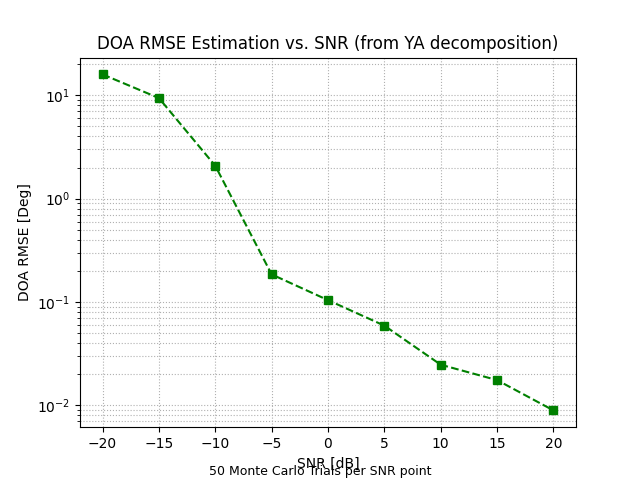
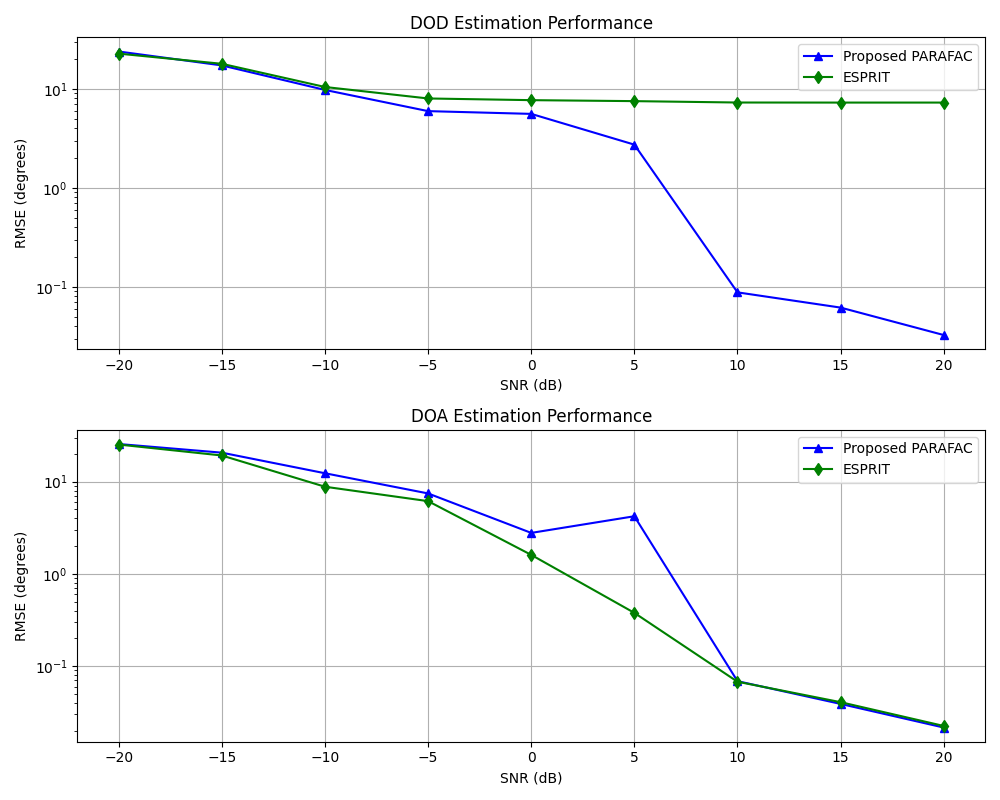
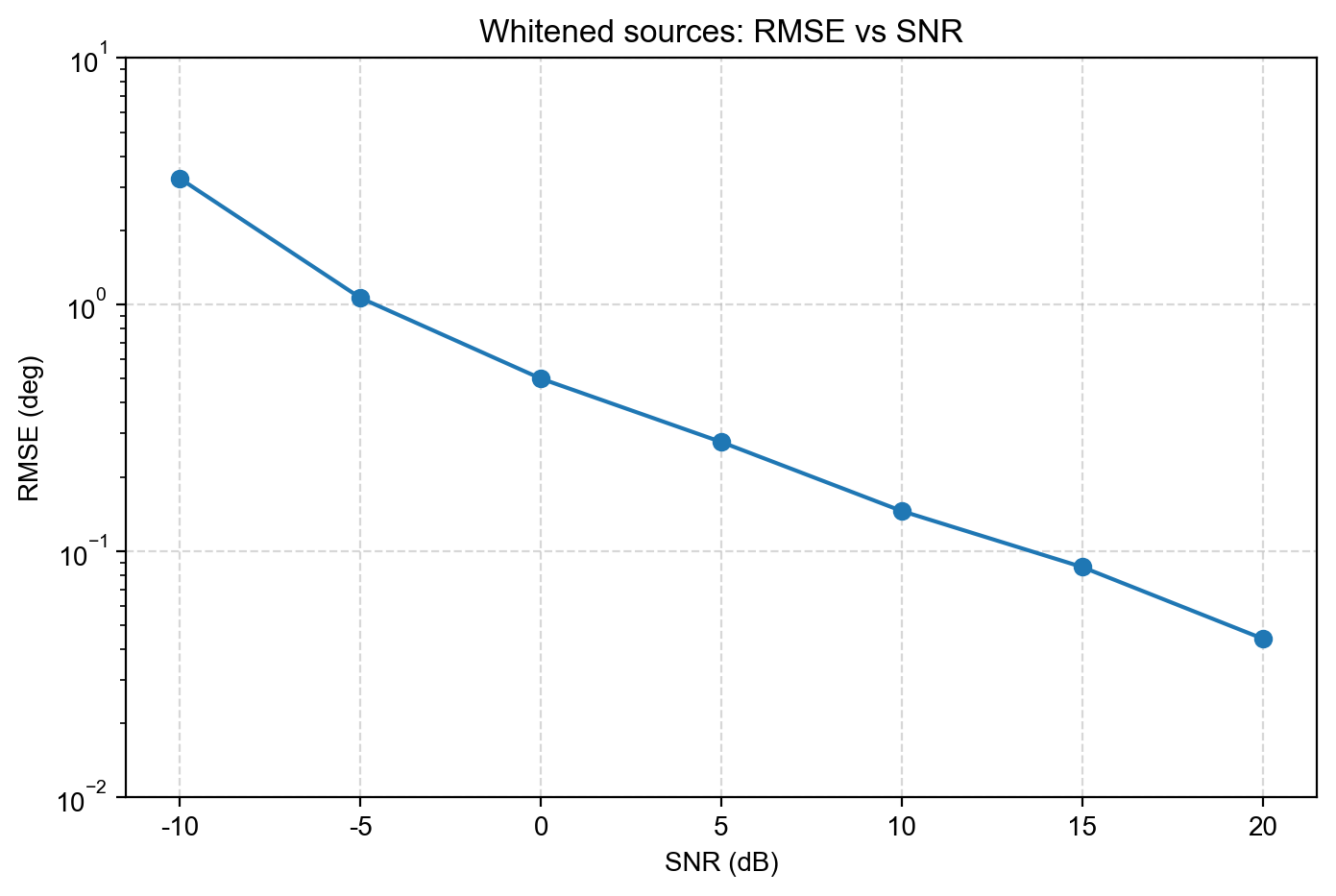
前面的算法都是矩阵算法——把数据压成一个二维表格来处理。但 MIMO 雷达的数据天然是三维的:发射天线 × 接收天线 × 脉冲/时间。强行压成矩阵,就像把立体照片压成平面图,很多空间信息就丢了。
张量是什么?
用最通俗的话说:
- 标量:一个数(0 维)
- 向量:一排数(1 维)
- 矩阵:一个表格(2 维)
- 张量:一个「数据方块」(3 维或更高维)
MIMO 雷达的接收数据就是一个三阶张量 Y∈CM×N×Q:第一个维度是发射通道,第二个是接收通道,第三个是脉冲数。
Mode-n 展开:把方块摊平
虽然张量是高维的,但有时候我们需要把它变回矩阵来做运算。Mode-n 展开就是把张量沿第 n 个维度「切开、摊平」:
- 沿发射维(Mode-1)展开:M×NQ 的矩阵
- 沿接收维(Mode-2)展开:N×MQ 的矩阵
- 沿脉冲维(Mode-3)展开:Q×MN 的矩阵
这就像把一个魔方拆开,按不同方向重新排成一列。
PARAFAC 分解:把复杂拆成简单
三阶张量最重要的分解方式是 PARAFAC(Parallel Factor Analysis)。它把一个张量拆成 R 个「最简单的积木」之和:
Y=r=1∑Rar∘br∘cr+Z
符号 ∘ 表示外积,意思是:(a∘b∘c)ijk=ai⋅bj⋅ck。也就是说,这个「积木」在三个维度上分别是向量 a,b,c,整体是一个三维的 rank-1 结构。
向量 ar,br,cr 分别来自三个因子矩阵 A,B,C。如果能从观测数据 Y 中恢复出这三个因子矩阵,就能读出目标参数。
PARAFAC 最关键的性质——唯一性:在适当条件下,因子矩阵 A,B,C 可以被唯一确定。这意味着不需要像矩阵 SVD 那样引入人为的正交约束,就能恢复出物理上有意义的解。
ALS 算法:交替求解
PARAFAC 没有闭式解,最常用的是 ALS(Alternating Least Squares):
- 固定 B 和 C,通过最小二乘更新 A。
- 固定 A 和 C,更新 B。
- 固定 A 和 B,更新 C。
- 循环直到收敛。
每一步都是凸优化问题,有解析解。虽然可能收敛到局部最优,但在大多数信号处理场景中表现很好。